Running Local LLMs on a Strix Halo Laptop
· 13 min read

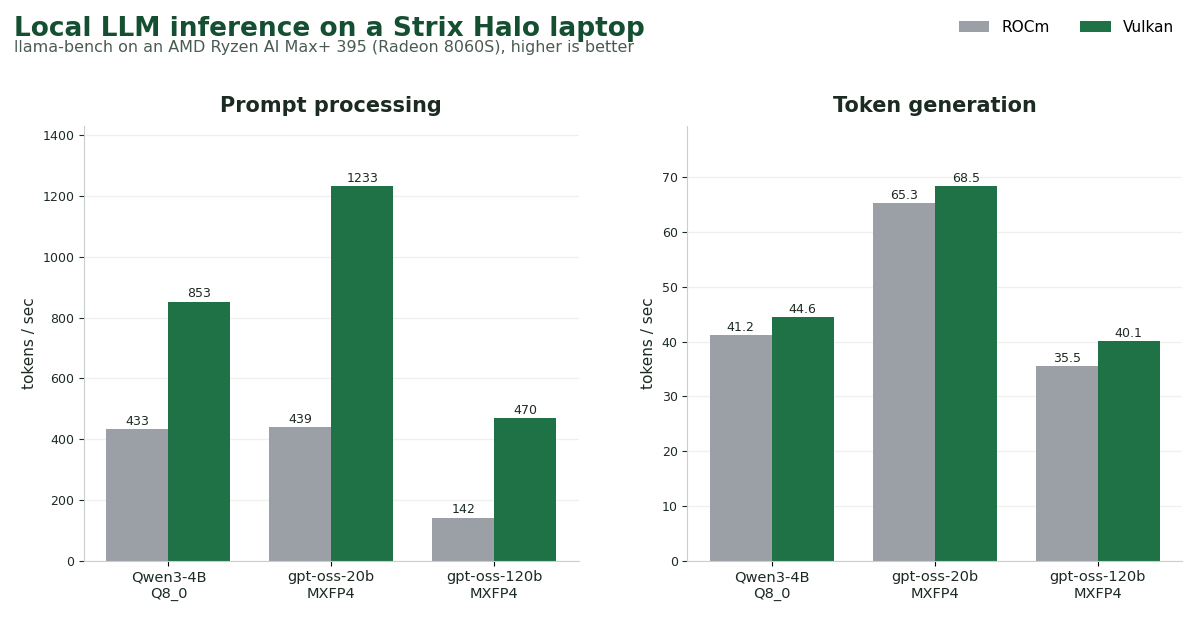
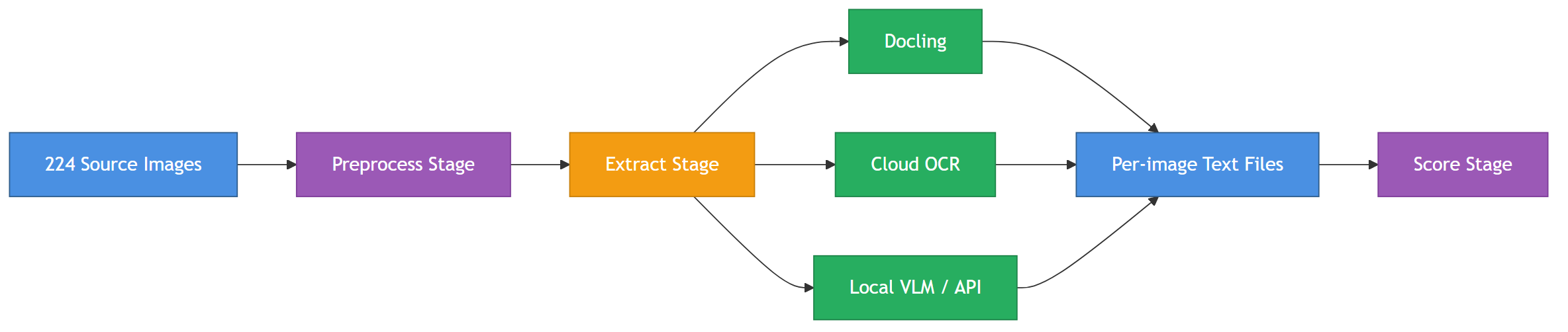
An AMD Ryzen AI Max+ 395 laptop with its integrated Radeon 8060S GPU and unified memory can run open-weight models from 4B parameters up to a 120B mixture-of-experts model, no cloud GPU needed. gpt-oss-120b generates around 35-40 tokens per second, and the 20B and 4B models are faster still. That's enough for the soviet.recipes project: this hardware can host a model large enough to attempt vision-language OCR locally.